
How to clean a very untidy data set with Freedom House country ratings, saved in an Excel sheet, which violates many principles of data organization in spreadsheets described in this paper by Karl Broman and Kara Woo, but otherwise is an invaluable source of data on freedom in the world?
Data source: https://freedomhouse.org/content/freedom-world-data-and-resources
The full code used in this post is available here.
I would do this:
Read in the file,
Transform everything into the long format - in R it’s much easier to deal with data with columns than in rows,
- Notice how the data read in in step (1) look like:
- column names ‘..odd_number’ contain the Civil Liberties rating (CL),
- ‘..even_number’ contain the Status category,
- the remaining columns contain the Political Rights rating (PR).
Use this observation to identify the type of data and make meaningful labels.
- Add a year variable knowing that: (a) there are 3 different quantities (CL, PR, Status), (b) 206 countries, and (c) the range of years is 1973-2018.
This is how the data look like in the Excel sheet:
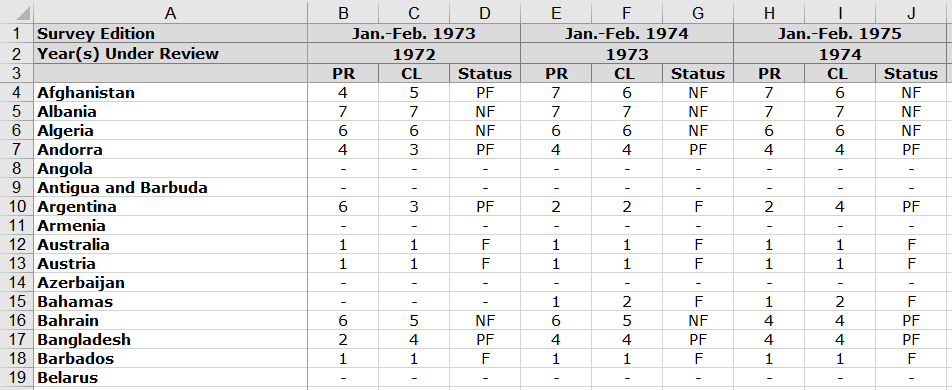
Figure 1: Excel sheet with Freedom House data.
fh <- import("data/Country and Territory Ratings and Statuses FIW1973-2018.xlsx",
sheet = 2, # read in data from the second sheet
na = "-") # recode "-" to missingThis is how the data look like after loading to R:
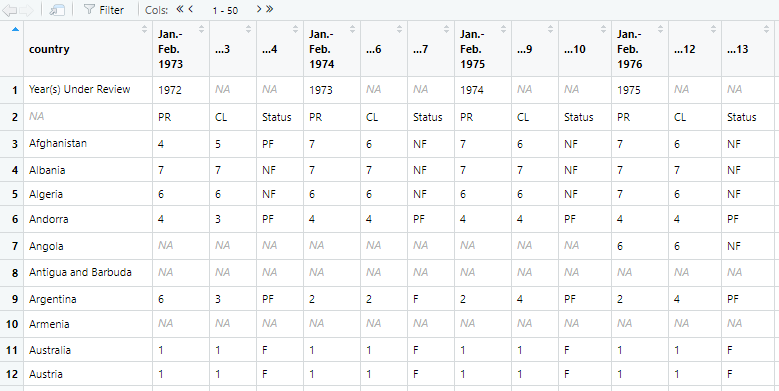
Figure 2: Untidy data frame with Freedom House data.
names(fh)[1] <- "country"
fh_clean <- fh %>%
filter(country != "Year(s) Under Review", # filter out the first row of data
!is.na(country)) %>% # filter out the second row of data
gather(var, value, 2:136) %>% # convert the whole data set to long format
mutate(# identify the type of data following (3) above
var1 = ifelse(substr(var, 1, 3) == "...", "CL/status", "PR"),
var1 = ifelse(var1 == "CL/status" &
as.numeric(substr(var, 4, 6)) %in% 2 == 0, "Status", "CL"),
year = rep(1973:2017, each = 3*206)) %>% # create the year variable following (4) above
select(country, year, var = var1, value)Voilà! This is how the data look like at the end:
head(fh_clean, 8)## country year var value
## 1 Afghanistan 1973 CL 4
## 2 Albania 1973 CL 7
## 3 Algeria 1973 CL 6
## 4 Andorra 1973 CL 4
## 5 Angola 1973 CL <NA>
## 6 Antigua and Barbuda 1973 CL <NA>
## 7 Argentina 1973 CL 6
## 8 Armenia 1973 CL <NA>